本文共 4214 字,大约阅读时间需要 14 分钟。
2019年1月,网站监测服务公司Catchpoint通过邮件列表和社交媒体进行了一项SRE调查。来自不同行业的188名SRE参与了这项调查,回答了如何管理事故以及事故后压力等一些问题。
今年是Catchpoint连续第二年调查SRE这个新兴的职业角色。去年的调查专注于SRE是谁,主要做什么。报告中探讨了SRE所使用的技能,工具集和企业文化,以确定团队和组织之间是否存在一套核心原则。
今年的调查研究了团队结构,中断,事故和事故后员工的压力。该调查希望回答事故对组织和响应人员有什么影响。组织专注于构建弹性系统并快速恢复,但这一关注点是否扩展到员工的弹性以及事故后压力的恢复?
调查结果主要有以下这些结论:
- 结论一:SRE仍然是一种新兴的实践方式。64%的受访者表示组织中SRE存在了不到三年。
- 结论二:事故处理占了SRE工作内容的大部分。49%的受访者表示过去一周处理过事故。
- 结论三:事故处理很有压力。79%的受访者表示事故处理的工作内容很有压力。
- 结论四:团队的支持可以减轻事故后的压力。在事故发生后感到有压力的SRE中,有67%的人认为公司不在乎他们的精神感受。
关于SRE
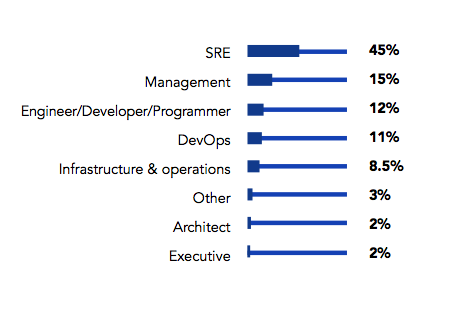
SRE工作人员有各种各样的头衔:45%的受访者头衔为SRE(站点可靠性工程师)。但其余的人自我认定为是SRE工作。当把SRE管理层(SRE经理,SRE主管等)包括在内时,这一百分比增加到49%。29%的SRE担任高级职位(包括架构师,高级/资深XX等),16%担任领导职位(经理,董事,副总裁或高管)。剩下的是初级或中级职位。
组织规模
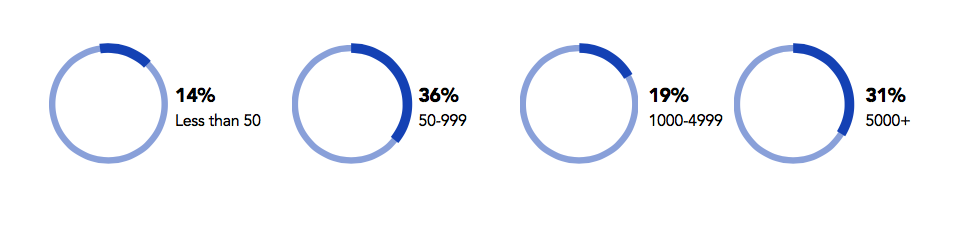
14%的受访者公司规模少于50人,36%的受访者公司规模在50-999人,19%的受访者公司规模在1000-4999人,31%的受访者公司规模在5000+人员。
结论一:SRE是新兴角色,还没有被完全定义
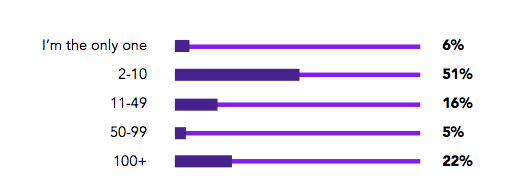
你的组织中有多少名SRE?
大多数受访者的组织中SRE团队不超过10人。6%的受访者反馈自己是组织中唯一的SRE人员。
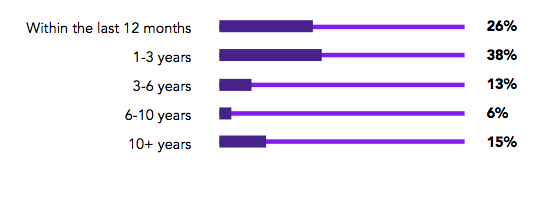
SRE团队组建了多久?
SRE概念的提出已经有15年了,但是这一角色仍然处于初始阶段。
SRE团队是如何组建的?
31%的受访者表示SRE团队是由运维/系统管理团队演变而来;
13%的受访者表示“我们把运维/工程/系统管理团队改名为SRE了”;9%的受访者表示,高层说我们现在在做SRE;2%的受访者表示我们雇了初级人员培训他们成为SRE。琐事(toil)的影响
琐事(toil)是手动,重复,可自动化和可线性扩展的战术工作,是SRE的主要关注点,主要来源于维护任务和非紧急的、与服务相关的消息。59%的人认为他们的组织中有太多的琐事,而且没有足够的自动化工具/流程来减少这些琐事。
对于“我们使用自动化来减少琐事“这一说法,没有人表示强烈赞同,而48.5%的人不同意或强烈不同意。
组织中有太多琐事

琐事的主要来源是:
- 39%的人表示是维护任务;
- 27%的人表示是非紧急性的服务相关消息;
- 16%的人表示是发布;
- 15%的人表示是on-call通知;
- 7%的人表示是非服务相关的消息。
我们使用了自动化来减少琐事

SLO
设置和监控SLO(服务级别目标)是SRE的一个关键方面。跟踪最广泛的SLO是服务可用性。
除了27%的受访者表示组织中没有SLO,其他所有具有SLO的SRE都会跟踪服务可用性。
我们为每个重要服务都设定了SLO:

我们的SLO包括

72%的人提到可用性,47%的人提到响应时间,46%的人提到延时,27%的人表示没有SLO。
事故对业务的影响
SLO不达标会对业务产生明显影响。一个SRE指出事故的后果是“世界会变成一团糟。”这话没错。
86%的受访者表示事故会降低客户满意度;
70%受访者反馈事故会使公司收入减少;57%的人反馈事故后员工生产力会下降;49%的人表示事故会造成客户流失;36%的人表示在发生事故的话会在社交媒体上产生不好的影响。小结
SRE仍处于初始阶段。SRE确保应用程序和服务的可靠性,这包括定义服务级别的可用性意味着什么。如果API可用,但响应请求需要5秒钟,能满足用户的期望吗?在组织准备好接受SRE工作之前(或者如果已经有SRE团队了),请考虑什么是可接受的SLO。从多个角度建立当前应用程序和服务性能的基准,并使用这些基准来指导创建SLO。
对于那些实践了很久SRE的公司,找到需要改进的地方。应该添加哪些额外的SLO?组织中目前有哪些琐事?有没有可能通过自动化来减少这些琐事?实施新SLO或启动新服务时,可能会创建哪些新的工作?
考虑SRE使用的工具。它们会增加琐事吗?能准确跟踪SLO吗?
结论二:事故处理占据SRE的大部分工作
调查中将事故定义为降低应用或服务质量的意外中断。根据故障或中断的范围、影响、复杂性和紧急程度确定事故的优先级。
88%的SRE通过警报和通知工具接收相关通知,但仍有少数人通过同事或用户联系服务台后才知道出了事故。
你上次处理事故是什么时候?
49%:一周以内;
34%:一月以内;10%:目前正在处理;4%:我不负责处理事故;4%:不记得了事故不可知也没办法提前准备,有些容易处理,有些则很难。近一半的受访者表示在职业生涯中遇到过持续一天以上的中断。
一周内处理多少起服务事故?
92%:少于5起;
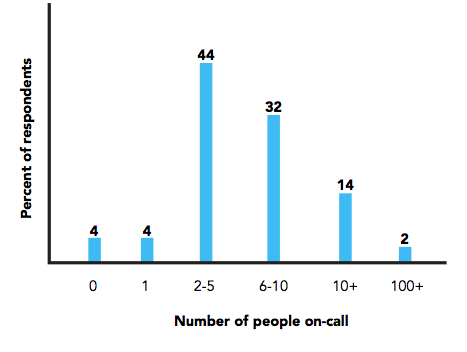
48%:少于1起;44%:5起;4%:6-10起;4%:超过10起团队里负责on-call轮班的有几个人?
On-call 轮换的情况各不相同。即使是少于50人的公司,他们的on-call轮换也有不同的规模。在少于50人的公司工作的受访者中,有30%的人表示团队中有2个人负责on-call。1%的人反馈团队中有130人负责on-call,另外有1%的人反馈团队中on-call轮班的有150人。
小结
考虑团队将有多少个SRE,以及他们是否能够充分支持应用和服务。给on-call轮班安排适当的人员,并确保他们可以访问警报和通知系统。
检查事故发生时是否存在一个处理模式。代码部署后会发生更多事件吗?如果是这样,请考虑在预生产或开发过程中进行额外的监控或测试。
结论三:处理事故的压力很大
调查中将事故后压力定义为事故发生后两天时间内身体和心理健康状况的变化。事故后压力可持续几分钟到两天时间不等。
在处理事故后会感到有压力吗?

11%:每次事故后都有压力;
68%:一些事故后有压力;21%:从来没感到过压力;那些经历事故后压力的人中,有67%在上周处理了事故,14%的人表示目前正在处理事故。
不想事故后有压力的话,一种方法是不对事故进行处理。18%的从未经历过事故后压力的人不记得上次他们处理事故是什么时候了,或者从来没有处理过事故。
另一方面,组织中唯一的SRE总会遇到一些压力。
事故后压力水平如何?
压力水平是主观的。某些人认为是低压力的事在另一些人看来可能是中等压力或高压力的事。
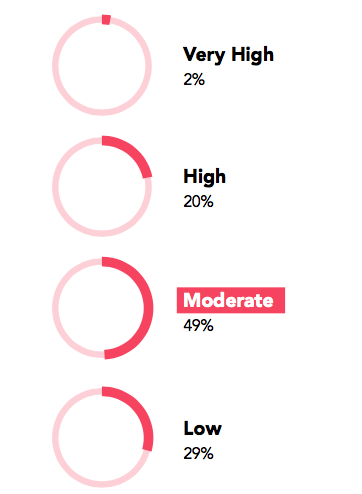
在处理严重问题时会感受到更多的压力吗?

最近一次处理事故之后有哪些身心变化?
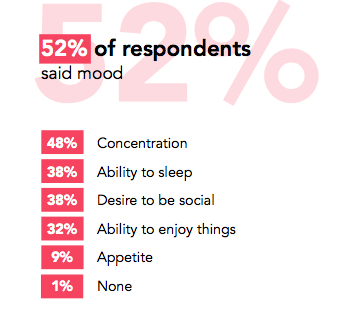
52%:情绪
48%:注意力38%:睡眠38%:社交32%:心情9%:胃口1%:无即使那些从未经历过事故后压力的人也在事故后也感受到某些上述情况的变化,虽然他们可能不会将此归类为压力。
做啥可以减轻压力?
61%:运动或散步
52%:花时间做自己喜欢做的事48%:晚上好好休息43%:和朋友相处35%:喝酒小结
SRE的工作很紧张。组织可以从流程和技术角度两方面采取措施来减轻他们的压力。一种方法是部署好警报,可及时进行通知。在总是遇到事故后压力的受访者中,20%是通过用户反馈服务台才发现事故的。如果员工在用户抱怨之前就收到通知,压力水平可能会降低。
如果组织已经有了警报和通知的解决方案,但SRE员工压力水平仍然很高,要考虑是否是由于警报疲劳造成的。是否因为没有对应用或服务的所有关键元素都监控到位而缺少了重要通知?
如果这些解决方案都已经到位,SRE还是压力很大,那可能是人的原因,也就是调查的最后一个结论。
结论四:团队的支持可以减轻事故后压力
认为公司关心自己身心健康的员工压力会小一些。经历过事故后压力的人中,76%不认为公司关心他们的身心健康或者没感觉到公司有关心过。从调查结果来看,SRE人员认为团队比公司更关心他们的精神状况。
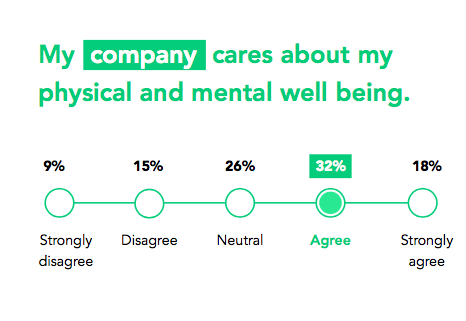
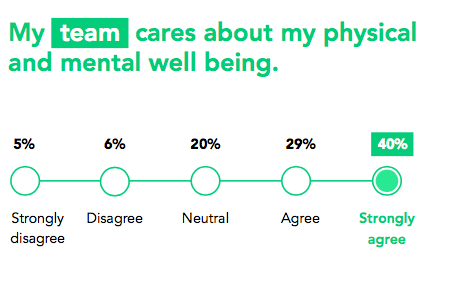
团队在意我的身心健康。5%完全不同意;6%不同意;20%没感觉;29%同意,40%完全同意。
你的组织如何减轻SRE的事故后压力?
调查中这个问题并没有提供“无”这一选项,但仍然有9%的回答是“无”。
61%:公司推行公平/免责文化
40%:有额外的休息时间38%:关心你在做什么7%:提供免费按摩7%:减少on-call轮班你认为你的团队在事故中/后支持你吗?
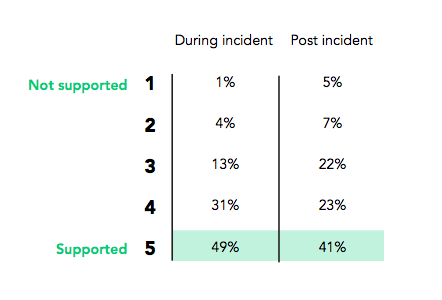
在事故中和事故后,一名SRE人员是否感受到团队支持会影响他的压力水平。80%的受访者表示在事故后感受到了团队的支持。反馈在某些或事故中感到压力的人中,64%表示受到团队支持。每次事故都感到压力的人中,有43%的人表示受到团队的支持。
小结
压力被认为是“工作的一部分”,但是不要忽视了压力对健康的影响。
免责文化(blameless post-mortem)的概念很好,但并不能消除SRE处理事故的压力。组织需要一些更具体的方法来减轻他们的压力。
对很多人来说,承认失败是有压力的。减少事故的发生,尤其是高优先级事故,将大大减轻压力。
对于on-call 轮班或处理事故的SRE,公司应该给予补偿。调查中受访者提到的一些补偿建议有:
- 为on-call提供加班费或者额外假期,一家公司将此称为“过载保护”,还挺形象。
- 定期进行事件后审查。
- 记录出错的地方,确定是否需要额外的技术或人力投资来解决问题。
- 在整个组织和团队中共享知识和信息。
你的公司有SRE团队吗,SRE们是否也如此亚历山大?欢迎大家留言交流。
转载地址:http://endda.baihongyu.com/